Part 4: Benchmarking DeepSeek Cost, Performance and Business Use Cases on AWS
Harnessing Open Source AI on AWS
Original Source of the blog post: Part 4: Benchmarking DeepSeek Cost, Performance and Business Use Cases on AWS
Blog was written with my colleague from Loka: Crhistian Cardona
We began this series on DeepSeek-R1 models on AWS by exploring the model’s general characteristics and how it fits within the current LLM and GenAI ecosystem. We then moved on to practical deployment, starting with AWS Bedrock, where we highlighted its special features, followed by a more flexible setup using AWS SageMaker by utilizing ML instances based on Nvidia GPUs and finally deployed it on EC2 Inferentia2-based instances for optimized performance.
This journey has taken us from theory to hands-on deployment, showcasing different AWS environments that each bring distinct characteristics and capabilities. Now we ask perhaps the most important questions of all: How do these models align with real business use cases? And how do we select the most suitable DeepSeek distilled model based on business needs?
In this final post, we will address these questions by:
Exploring benchmarks for DeepSeek models, including latency comparisons and other key performance metrics across different deployment options discussed in previous posts. Defining common business use cases and evaluating which models, both from DeepSeek and other available AWS models best fit each scenario. Breaking down selection criteria, considering cost, performance, capabilities and complexity for each use case. Our goal is not to provide a rigid manual for solving a single use case but rather to present a structured approach to analyzing business needs and selecting the most appropriate model. By the end of this final entry to the series you’ll have a clear framework for making informed AI deployment decisions based on your specific requirements.
Let’s dive in!
Benchmarking: Performance Across AWS Deployments
To evaluate performance across different AWS environments, we conducted simple benchmarking using the first 20 sample prompts from the classical OpenAI’s benchmark dataset for reasoning, GSM8k, because we are testing the DeepSeek-R1 Distill Llama 8B model. Keep in mind that these results will be appropriate for all open-source models of similar sizes. These prompts were applied to models deployed on Amazon Bedrock, AWS SageMaker (utilizing ML instances based on Nvidia GPUs, ml.g6.2xlarge) and pure EC2 instances (utilizing the latest Inferentia2 chips called inf2.8xlarge). Each sample prompt first was used to trigger a cold start of the model by doing three runs which are not used for calculating the metrics and then we ran five more runs of the same prompt which are used to calculate the metrics that are utilized in this benchmarking process
Our benchmarking dataset captures system performance metrics, focusing on response times and variability across different endpoints. Key metrics include:
- Average Latency (ms): Mean response time in milliseconds
- 50th Percentile (Median) Latency (ms): The middle value in response times
- 95th Percentile Latency (ms): High-end response latency
- Minimum and Maximum Recorded Latencies (ms): Performance variability
- Standard Deviation (ms): Measure of response time variability, indicating consistency
We also analyzed prompt and response characteristics such as input length, response length and the actual generated response to see if the model returns the expected response independent of the service on which it is deployed.
Figure 1. Average Latency per Service
The benchmark results showcased on the Figure 1 reveal that Bedrock delivers the lowest average latency at approximately 10,975 ms, significantly outperforming both SageMaker at about 32,339 ms and EC2 at roughly 53,125 ms. This suggests that the deployment through Bedrock’s Custom Model Import provides a quicker overall response, potentially offering a better experience for applications where latency is a critical factor.
A deeper look into the detailed latency metrics from Figure 2 further underscores these observations. The P50 latencies show that Bedrock has a median latency of 6,137 ms, which is much lower than SageMaker’s 26,212 ms and EC2’s 59,882 ms, reinforcing Bedrock’s consistent performance. Additionally, the P95 values reveal that while all services experience higher latencies under peak conditions, Bedrock remains relatively lower at 21,904 ms compared to the much higher values for SageMaker (55,800 ms) and EC2 (76,853 ms). The range between the minimum and maximum latencies also illustrates that Bedrock has a narrower performance band from about 2,047 ms to 41,984 ms whereas SageMaker and EC2 display wider ranges, with particularly notable extremes on SageMaker, indicating occasional severe delays.
Examining the variability in response times shown in the Figure 3, Bedrock again appears to be the most consistent, with a standard deviation of about 5,971 ms compared to SageMaker’s 16,964 ms and EC2’s 18,867 ms. Lower variability in Bedrock’s latency indicates a more stable performance, while the higher standard deviations seen in SageMaker and EC2 point to greater fluctuations that could lead to occasional performance hiccups.
Figure 2. P50 Latency, P95 Latency, Min Latency and Max Latency per Service
Figure 3. The standard deviation of latency between services
When performance consistency and minimal latency are paramount, especially in applications requiring near real-time responses, AWS Bedrock emerges as the optimal choice. Its deployment through Custom Model Import consistently delivers the lowest average latency (approximately 10,975 ms) and exhibits relatively tight response variability. This makes Bedrock highly suitable for user-facing applications, interactive services or scenarios where a predictable response time is critical.
AWS SageMaker, deployed on GPU-backed ml.g6.2xlarge instances, offers significant benefits for workloads that demand intensive computation and GPU acceleration. Although its average latency is higher (around 32,339 ms) with more variability, SageMaker is ideal for training, fine-tuning or serving models that require robust computational resources. Its flexibility in handling complex, resource-demanding tasks makes it a better fit for development environments and scenarios where GPU-optimized performance is more important than ultra-low latency.
For use cases where cost efficiency or large-scale batch processing is the priority rather than immediate response times, leveraging pure EC2 instances equipped with the latest Inferentia2 chips (inf2.8xlarge) can be justified. Despite having the highest average latency (about 53,125 ms) and broader variability, this option may be well-suited for background processing or non-interactive applications where throughput and cost savings outweigh the need for rapid responses.
Calculating: Costs Across AWS Deployments
Beyond performance, we also incorporated cost analysis for each deployment setup, detailing instance types used and associated pricing. This cost-performance comparison is particularly relevant for the next section, where we explore real-world use cases and benchmark these results against other models available in AWS environments (Figure 4). This approach provides a practical perspective on both efficiency and cost-effectiveness, aiding in informed decision-making for AI model deployment.
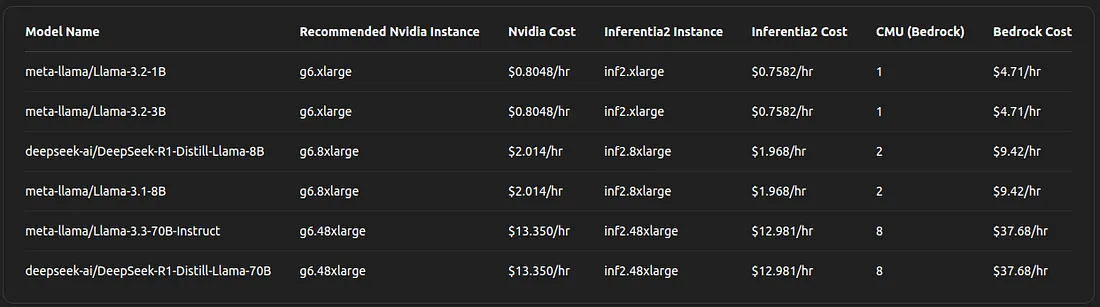 Figure 4. Cost analysis of deployment different size models on different AWS Services
Figure 4. Cost analysis of deployment different size models on different AWS Services
The cost analysis reveals interesting tradeoffs between direct instance deployments (using Nvidia‐ or Inferentia2‐based instances) and AWS Bedrock’s managed Custom Model Unit (CMU) pricing. Similar to the performance analysis, the data shows that the relative cost differences vary with model size and complexity.
For models like meta-llama/Llama-3.2–1B and Llama-3.2–3B, the recommended Nvidia-based instance (g6.xlarge) costs about $0.8048/hr, while the corresponding Inferentia2 instance (inf2.xlarge) comes in slightly lower at $0.7582/hr. In contrast, AWS Bedrock requires 1 CMU at $4.71/hr — roughly a sixfold premium compared to the hardware options. This indicates that for smaller models, direct deployments on GPUs or Inferentia2 chips are more cost-efficient even though Bedrock may offer additional benefits in terms of managed services and performance consistency.
Moving to the 8B model category (deepseek-ai/DeepSeek-R1-Distill-Llama-8B and meta-llama/Llama-3.1–8B), the recommended instance shifts to a more powerful g6.8xlarge, costing around $2.014/hr for Nvidia and $1.968/hr for Inferentia2. Here, Bedrock’s pricing jumps to 2 CMU at $9.42/hr. Although the absolute cost difference is higher for Bedrock, the multiplier compared to direct hardware deployment decreases to about 4.7 times. This narrowing gap suggests that as model size increases, the relative premium for Bedrock diminishes, potentially making it a more attractive option when considering factors beyond cost alone.
For the largest models, such as meta-llama/Llama-3.3–70B-Instruct and deepseek-ai/DeepSeek-R1-Distill-Llama-70B, the recommended instances are significantly more powerful, g6.48xlarge for Nvidia at $13.350/hr and inf2.48xlarge for Inferentia2 at $12.981/hr. Meanwhile, Bedrock’s requirement scales to 8 CMU at $37.68/hr. At this scale, the cost multiplier for Bedrock relative to direct deployments drops to approximately 2.8–2.9x. This reduction in the relative cost premium suggests that for high-end, computationally intensive models, the managed service and streamlined operations provided by Bedrock could justify the higher hourly rate.
The cost difference between Nvidia-based and Inferentia2-based instances is marginal, with Inferentia2 generally offering a slight cost advantage. Both are attractive for scenarios where minimizing operational costs is critical, especially for lower-latency, real-time applications.
While Bedrock incurs a premium especially for smaller models the gap narrows significantly as model complexity increases. For larger models, the managed service benefits and potential performance consistency improvements may well offset the higher cost, making Bedrock a compelling option when ease of use and operational efficiency are prioritized.
Over the past few weeks, AWS has made significant strides in expanding Bedrock’s capabilities. Not only is DeepSeek now available as a JumpStart-imported model, but it’s also fully integrated into Bedrock as a fully managed, serverless model, which is ready to use out of the box. As we’ve demonstrated throughout this series, these models can also be deployed on external infrastructure using SageMaker, offering flexibility for more advanced or customized use cases.
One of the most compelling aspects of DeepSeek on Bedrock is its affordable pricing: currently around $0.00135 per 1K input tokens and $0.0054 per 1K output tokens. This positions DeepSeek as a cost-effective option for a wide range of applications from internal tools and chatbots to large-scale enterprise analytics making it easier than ever to build with generative AI at scale.
In summary, the choice between these deployment methods hinges on the specific requirements of the application. For cost-sensitive or batch processing scenarios, the relatively lower hourly rates of Nvidia or Inferentia2 instances are advantageous. However, for applications where performance consistency, ease of deployment and managed service benefits are critical particularly with larger models, AWS Bedrock’s pricing becomes more competitive despite its higher nominal cost.
Choosing the Right GenAI Model for Your Use Case: A Practical Guide
As businesses increasingly integrate Generative AI (GenAI) into their workflows, selecting the right model for the job is critical. However, several factors must be considered to ensure feasibility and optimal performance for specific use cases.
When matching a GenAI model to a business problem, we need to assess key factors such as:
- Cost: Budget constraints and operational expenses
- Speed: How quickly responses are needed
- Model Capabilities: Performance level required for the problem’s complexity
- Problem Scope: The depth and nature of the challenge at hand
With the release of new models like DeepSeek-R1 models, Llama models, Gemma Models, etc, businesses now have more options than ever. These models offer expanded context windows, cost-efficient lightweight versions and high-performance alternatives, making it easier to find a model that aligns with specific business and technical needs.
To guide decision-making, we will focus on models that are readily deployable on AWS, using Amazon Bedrock, SageMaker JumpStart, EC2 and inference instances.
Two Key Considerations for Model Selection
When selecting a GenAI model, we can categorize the decision-making process into two key dimensions.
Matching the Model to the Use Case
Different models excel in different business scenarios. Below are five primary applications of GenAI
- Case 1–Enterprise Applications: Customer support, business intelligence and financial analysis
- Case 2–Research & Scientific Computing: Complex reasoning, mathematical problem-solving and multilingual tasks
- Case 3–Conversational AI & Chatbots: Customer service bots, virtual assistants and real-time interactions
- Case 4–Content Generation & Creative AI: Marketing, blog writing, code generation and document processing
- Case 5–Multimodal AI: Processing and generating text, images, videos, code and speech
Choosing the Right Model Based on Complexity & Capability
Models can be categorized into three tiers based on size (parameters) and performance.
- Small Models: Lightweight, cost-efficient and suitable for simple tasks.
- Medium Models: Balanced performance, optimized for general business applications.
- Large Models: Designed for advanced reasoning, deep learning tasks and multimodal capabilities.
By combining these two perspectives matching the problem to the model’s capabilities, we can streamline model selection, ensuring the best fit for a given business challenge while optimizing for performance, cost, and deployment feasibility.
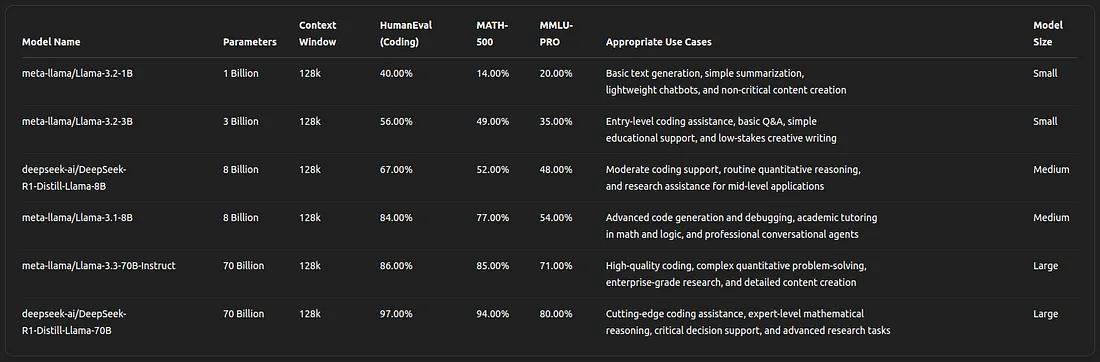 Figure 5. Different size models and their use-cases
Figure 5. Different size models and their use-cases
Final Thoughts & Conclusion
Throughout this series, we’ve explored how DeepSeek-R1 models (or any open-source model) can be deployed across AWS services Bedrock, SageMaker and EC2, each offering distinct trade-offs in performance, cost and flexibility. By benchmarking these environments and analyzing real-world use cases, we’ve outlined actionable insights to guide deployment decisions.
AWS Bedrock is the best choice for real-time, low-latency applications such as chatbots and interactive tools, delivering consistent performance with an average latency of ~11,000 ms and minimal variability. However, its fully managed nature comes at a premium, making it less cost-effective for smaller models. SageMaker, powered by Nvidia GPU-based instances, offers a balance of flexibility and computational power, making it ideal for development, fine-tuning and workloads requiring GPU acceleration, though it has a higher latency (~32,000 ms). On the other hand, EC2 Inferentia2 is optimized for cost efficiency, particularly for large-scale, non-real-time workloads such as batch processing, offering lower hourly rates but higher latency (~53,000 ms).
Model size is another critical factor when selecting the right deployment strategy. Small models (1B–3B parameters) are cost-effective for simpler tasks like text generation and basic Q&A but often struggle with complex reasoning. Medium-sized models (8B parameters), such as DeepSeek-R1-Distill-Llama-8B, strike a balance between efficiency and performance, making them suitable for coding support, routine analysis and mid-tier enterprise applications. Large models (70B parameters) are best suited for advanced use cases like scientific research and critical decision-making but come with significantly higher infrastructure costs.
Use case alignment further refines deployment choices. For enterprise applications requiring reliability, medium-sized models (8B) or Bedrock’s managed service provide a robust solution. Research and scientific computing, which often demand intensive computation, benefit from large models (70B) deployed on SageMaker or Inferentia2. For conversational AI, Bedrock is the preferred choice for low-latency interactions, while smaller models can be leveraged for lightweight chatbot applications. Content generation needs vary in complexity, with medium-to-large models being ideal DeepSeek-R1–70B excels in producing high-quality outputs. Finally, for multimodal AI, models like Llama 3.3 70B offer broader capabilities across various domains.
March 2025 has brought exciting new models available on AWS Bedrock. While not open source, the addition of models like Claude 3.7 Sonnet from Anthropic and Amazon Titan Nova Pro has opened up even more possibilities. These models offer impressive performance, support features like distillation for improved efficiency and come with competitive pricing, making them well-suited for business use cases ranging from high-performance reasoning tasks to scalable, cost-efficient deployments.
Choosing the right deployment option ultimately depends on the priorities of your business. If real-time performance is the top priority, Bedrock is the best option despite its higher cost for smaller models. For teams needing more flexibility, SageMaker with GPU instances is ideal for development, fine-tuning and hybrid workloads. If cost efficiency is the main concern, EC2 Inferentia2 is well-suited for batch processing and non-urgent tasks. For complex tasks requiring advanced reasoning and coding capabilities, larger models like DeepSeek-R1-Llama-Distill-70B justify their higher costs with superior performance. By leveraging the structured framework provided in this series, you can confidently navigate these tradeoffs, ensuring that your GenAI investments align with your specific needs and deliver tangible value.